एक तेलुगु चरित्र क्यों एप्पल उपकरणों को ला रहा है
ऐप्पल में कुछ महीनों में एक छोटी गाड़ी हो रही है। अब हमारे पास iPhones में टेक्स्ट-रेंडरिंग कार्यक्षमता में एक नई, गंभीर बग है। बग एक एकल तेलुगू चरित्र द्वारा ट्रिगर किया जाता है जो एक आईफोन को चरित्र युक्त अधिसूचना प्राप्त करके एक अटूट बूट लूप में प्रवेश कर सकता है। आइए इस बात का पता लगाएं कि क्यों एक ही चरित्र आईओएस के साथ ऐसी बड़ी समस्याएं पैदा कर सकता है।
नोट: तेलुगु बग के लिए एक फिक्स आईओएस के नवीनतम संस्करण (11.2.6) में उपलब्ध है। यदि तेलुगू चरित्र ने आपके ऐप या डिवाइस को लॉक कर दिया है, तो आईट्यून्स के माध्यम से अपना आईफोन बहाल करें और आईओएस के नवीनतम संस्करण में अपडेट करें। यदि आपका आईफोन बूट लूप में फंस गया है, तो आपको इसे पहचानने के लिए आईट्यून्स प्राप्त करने के लिए इसे डिवाइस फर्मवेयर अपडेट (डीएफयू) स्थिति में रखना होगा। समाप्त होने पर, अपने डिवाइस को अपने सबसे हालिया बैकअप से पुनर्स्थापित करें, जिसे आपने आशापूर्वक बनाया है।
तेलुगु क्या है?

तेलुगू बोली जाने वाली भाषा है और भारत के कुछ हिस्सों में विशेष रूप से आंध्र प्रदेश, तेलंगाना राज्य और यानम शहर में लिखी गई है। अरबी और अन्य ब्राह्मण स्क्रिप्ट जैसे कई स्क्रिप्ट-आधारित भाषाओं की तरह, तेलुगू यूनिकोड चरित्र सेट की कुछ विशेष विशेषताओं का उपयोग कंप्यूटर स्क्रीन पर अपने पात्रों को प्रदर्शित करने के लिए करता है।
जबकि अधिकांश लैटिन अक्षरों को एएससीआईआई संगतता के लिए एकल 8-बिट यूनिकोड कोड बिंदु द्वारा दर्शाया जाता है (उदाहरण के लिए, अक्षर ए यूनिकोड कोड पॉइंट U+0041 01000001 पर मौजूद है, जिसे 01000001 बाइनरी में 01000001 ), स्क्रिप्ट या गैर- लैटिन अक्षरों में आम तौर पर एक से अधिक यूनिकोड कोड बिंदु को उनके वर्णों का प्रतिनिधित्व करने के लिए जोड़ दिया जाता है।
यह तेलुगू जैसी भाषाओं के लिए विशेष रूप से सच है, जो क्लस्टर में अक्षरों के भाषाओं के संस्करणों को जोड़ती है। अंग्रेजी के स्टाइलिस्ट लिगचर के विपरीत, प्रत्येक तेलुगू पत्र के बीच संबंध भाषाई रूप से महत्वपूर्ण है। इसे समायोजित करने के लिए, यूनिकोड में अक्षरों को जोड़ने की जटिल प्रणाली शामिल है, प्रत्येक एक दूसरे के लिए अपने कोड बिंदु द्वारा प्रतिनिधित्व किया जाता है।
यूनिकोड कोड बिंदुओं की तीव्र संख्या को ध्यान में रखते हुए, यह निकट-अनंत विविधता बना सकता है। ये बिंदु एक सुस्पष्ट चरित्र प्रस्तुत करने के लिए एक साथ गठबंधन करते हैं। इस तरह यूनिकोड को हर संभव तेलुगु शब्द के लिए यूनिकोड कोड बिंदु की आवश्यकता नहीं है। इसके बजाए, यूनिकोड एक ही चरित्र की तरह प्रदर्शित होने वाले शब्दों को बनाने के लिए तेलुगू व्यंजन, स्वर और डायक्रिटिक्स ("वायरमा") को एक साथ जोड़ता है। यह अरबी जैसे लिगरेचर के लिए ऑर्थोग्राफिक नियमों वाली अन्य भाषाओं पर लागू होता है।
क्या क्रैश का कारण बनता है?

समस्या कोड बिंदु U+200C पर शून्य चौड़ाई गैर-योजक (ZWNJ) से संबंधित प्रतीत होती है। ZWNJ अनुरोध करता है कि दो आसन्न पात्र उनके विशिष्ट लिगरेचर के बिना प्रस्तुत करते हैं। अंग्रेजी में, एक ZWNJ वर्णों को एफएफ को अपने मानक कनेक्शन लिगरेचर के साथ मुद्रित करने से रोकता है, बजाय प्रत्येक एफ को अलग करता है। लेकिन जब चार तेलुगू कोड बिंदुओं के एक विशिष्ट सेट के साथ संयुक्त होते हैं (जिनमें से सभी को एक क्लस्टर में जोड़ना चाहिए), किसी कारण से आईओएस परिणाम को सही तरीके से प्रदर्शित नहीं कर सकता है।
कुछ ने अनुमान लगाया है कि ऐप्पल का सैन फ्रांसिस्को फ़ॉन्ट चरित्र प्रदर्शित नहीं कर सकता है, जबकि अन्य ने कहा है कि ऐप्पल का उपयोग करने वाली विशिष्ट प्रतिपादन प्रक्रिया दोष है। जो कुछ भी सही कारण है, चरित्र को प्रस्तुत करने का प्रयास संदेश और व्हाट्सएप से स्प्रिंगबोर्ड तक जो कुछ भी प्रस्तुत कर रहा है उसका नाटकीय दुर्घटना का कारण बनता है। यूनिकोड कोड बिंदु जो चरित्र ("ज्ञान" अर्थ "ज्ञान") बनाते हैं, नीचे दिए गए हैं:
U+0C1Cजे (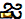 )
)U+0C4Dएक वायरमा, या डायक्रिटिक मार्क ( )
)U+0C1Eन्या (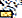 )
)U+200Cशून्य चौड़ाई गैर-योजकU+0C3E(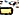 )
)
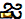 )
) )
) )
) )
)लेकिन हम अकेले शून्य चौड़ाई गैर-जॉइनर (जेडब्लूएनजे) को भी दोष नहीं दे सकते। यह किसी भी मुद्दे के बिना निर्दोष परिवार इमोजिस (????) में भी प्रयोग किया जाता है। यह कुछ विशिष्ट कोड बिंदुओं और ZWNJ का एक विशिष्ट संयोजन प्रतीत होता है। चोट के अपमान को जोड़ते हुए, ऐसा लगता है कि ज़ेडब्लूएनजे या तो इस तेलुगु क्लस्टर पर प्रतिपादन पर कोई विशेष प्रभाव नहीं पड़ता है या यह पहले स्थान पर भी नहीं होना चाहिए।
अन्य ब्राह्मण स्क्रिप्ट समस्याएं
हालांकि, तेलुगू इस मुद्दे के साथ एकमात्र भाषा नहीं है। बंगाली और देवनागरी, जो यूनिकोड का उपयोग अपनी ब्राह्मण स्क्रिप्ट के लिए समान तरीके से करते हैं, वही समस्या है। मनीष गोरेगाकार एक विचित्र और विस्तृत ब्लॉग पोस्ट लिखते हैं जो सटीक क्रैश केस को और भी आगे तोड़ देता है:
कोई अनुक्रम
देवनागरी, बंगाली और तेलुगु में, जहां:1.
consonant2प्रत्यय-शामिल है (pstf/pstf)
2.consonant1एक रेफ-फॉर्मिंग पत्र नहीं है
3.vowelमें दो ग्लिफ घटक नहीं होते हैं
निष्कर्ष: यह ऐप्पल द्वारा क्यों नहीं पकड़ा गया था?
यह बग कैसे प्राप्त हुआ यह समझने के लिए, आपको खुद को ऐप्पल के जूते में रखना होगा। निश्चित रूप से, यह चरित्र संयोजन तेलुगु भाषा में कुछ सुपर अस्पष्ट शब्द नहीं है। लेकिन आईफोन में दर्जनों भाषाओं के लिए समर्थन शामिल है। यूनिकोड में सचमुच अरबों संभावित संयोजन हैं। रिलीज से पहले यूनिकोड बग के लिए उस बहुत विविधता के साथ सार्थक परीक्षण, नियमित सॉफ़्टवेयर अपडेट मूल रूप से असंभव बना देगा।
हालांकि, त्रुटि को इस नुकसान के कारण नहीं होना चाहिए था। किसी टेक्स्ट संदेश की सामग्री के आधार पर फ़ोनों को ब्रिक नहीं किया जाना चाहिए। जबकि हिंडसाइट निश्चित रूप से 20/20 है, ऐसा लगता है कि चरित्र को एक प्रश्न चिह्न बॉक्स के रूप में प्रस्तुत करना ( ) स्प्रिंगबोर्ड को दुर्घटनाग्रस्त करने से बेहतर होगा।





